-
클라우드 기반 MLOps와 로봇 개발: 데이터 수집부터 실시간 배포까지Humanoid 2025. 6. 3. 08:26728x90SMALL

현대 AI 로봇 개발에는 MLOps라 불리는 머신러닝 파이프라인 운영 개념이 필수적으로 도입되고 있습니다. 이는 소프트웨어 개발의 DevOps처럼, 데이터 수집 → 모델 학습 → 배포 → 피드백 수집의 주기를 자동화하고 반복함으로써 지속적으로 성능을 향상시키는 프로세스입니다.
테슬라의 Optimus 개발과 NVIDIA Cosmos를 활용한 로봇 개발 모두 본질적으로 이러한 MLOps 파이프라인을 따르고 있습니다. 각각의 접근 방식에 차이는 있지만, 공통적으로 클라우드 인프라를 활용한 대규모 데이터 처리와 모델 최적화가 핵심에 자리합니다. 아래에서는 Optimus (테슬라)와 Cosmos (NVIDIA 에코시스템) 사례를 염두에 두고, 클라우드 기반 로봇 MLOps 파이프라인을 단계별로 살펴보겠습니다:
1) 데이터 수집(Data Collection) 및 생성
첫 단계에서는 학습에 필요한 데이터를 대량으로 확보합니다. 테슬라의 경우 전 세계에 분포한 자사 차량 플릿과 프로토타입 로봇을 통해 현실 데이터를 수집합니다. 테슬라 차량은 매분 수천만 개의 이미지 프레임에 해당하는 카메라 영상을 백엔드로 업로드하며, 이는 “테슬라 플릿이 매 분당 약 2,380분의 주행 영상을 기록한다”는 수치로 환산될 정도의 규모입니다[notateslaapp.com].이를 통해 불과 6일이면 2천만 시간 분량의 주행 영상이 축적되어, FSD와 Optimus의 인지 능력을 향상시키는 재료가 됩니다. 이처럼 방대한 실제 주행/로봇 데이터는 다양한 기후, 지형, 조도, 행동 패턴을 망라하기 때문에 모델이 현실 세계를 학습하는 데 필수적입니다.
반면, NVIDIA Cosmos를 중심으로 한 접근에서는 현실 데이터 수집량이 한계가 있는 기업들을 위해 합성 데이터 생성을 적극 활용합니다. 예를 들어 자율주행 스타트업은 초기에 갖고 있는 수십 시간 분량의 주행 영상이나 로봇 센서 데이터를 Cosmos에 입력해 확장된 가상 데이터를 생성해낼 수 있습니다notateslaapp.com]. Cosmos의 생성 모델은 입력 영상을 학습해 그와 비슷하지만 변형된 새로운 영상 시나리오들을 무한히 만들어내며, Isaac Sim과 결합해 다양한 환경 변수와 물리 상호작용이 반영된 센서 데이터까지 합쳐줍니다.
이렇게 얻은 합성 데이터는 현실 데이터의 부족을 메워줄 뿐 아니라, 현실에서는 드문 이벤트 (예: 희귀한 장애물 등장 상황 등)도 의도적으로 많이 포함시킬 수 있다는 장점이 있습니다. 실제 테슬라 또한 기본적으로는 실데이터 위주지만, 필요에 따라 시뮬레이션으로 생성한 합성 데이터를 보강하여 학습에 활용하고 있습니다.
2) 데이터 레이블링 및 전처리(Data Labeling & Preprocessing):

원시 데이터(현실이든 합성이든)를 머신러닝에 바로 쓰려면, 의미있는 레이블/주석 및 정리가 필요합니다. 테슬라의 FSD/Optimus 파이프라인에서 혁신적인 부분은 대규모 자동 레이블링(autolabeling) 시스템입니다. 테슬라가 구축한 거대한 데이터 라벨링 파이프라인은 각 프레임의 도로 객체, 차선, 보행자 등을 AI와 클라우드 연산으로 자동으로 태깅하며, 필요한 경우 소수의 인력 검수만 거쳐 수십만~수백만 장의 이미지에 일관된 레이블을 달아냅니다.
특히 여러 카메라 시점과 라이다 점군을 종합해 4차원(시간+공간)으로 추적 레이블을 입히는 등, 수작업으로 불가능한 수준의 정밀 작업도 수행합니다[youtube.com]. 이 과정은 매우 연산 집약적이어서, 테슬라는 Dojo 슈퍼컴퓨터를 데이터 라벨링 작업에도 활용할 계획을 밝혔습니다. 즉, Dojo의 병렬처리 성능으로 영상들을 분석해 객체 경계를 그리고, Segmentation/Depth 등을 산출하는 등의 사전 연산을 함으로써 데이터 준비 단계를 단축시키겠다는 것입니다.
반면 Cosmos/Isaac Sim을 활용하는 경우 시뮬레이션 자체가 ground-truth 레이블을 제공하므로 별도의 라벨링 단계가 간소화됩니다. 가상환경에서는 로봇이 상호작용하는 모든 객체의 종류와 위치를 정확히 알고 있으므로, 합성된 이미지에 대해 정답 출력(예: 3D bounding box 좌표)를 자동 생성해 같이 저장합니다. 다만 완전히 현실과 동떨어진 합성 데이터만으로 훈련하면 모델이 편향될 수 있기 때문에, NVIDIA의 권고는 실제 데이터로 모델을 미세조정하고 합성 데이터 비율을 적절히 조율하라는 것입니다[notateslaapp.com].
요약하면 이 단계에서는, 테슬라는 자율주행 러닝에서 축적한 최적화된 대용량 데이터 레이블링 파이프라인으로 Optimus까지 데이터 준비를 확장하고 있고, NVIDIA 생태계에서는 시뮬레이션으로 레이블 비용을 줄이면서 필요시 현실 데이터로 튜닝하는 전략을 취합니다.
3) 모델 학습(Training) 및 대규모 최적화
준비된 거대한 학습 데이터셋을 바탕으로 신경망 모델을 훈련하는 단계입니다. 이 단계에서 클라우드 인프라의 역할이 가장 두드러집니다. 테슬라는 자체 GPU 클러스터와 Dojo를 결합하여 수십억개의 가중치를 가진 거대 비전 모델을 훈련하고 있습니다. 실제 2023년 일론 머스크는 “남들이 우리를 따라하려면 수십억 달러 상당의 훈련 컴퓨팅 파워가 필요할 것”이라고 언급할 정도로, 테슬라는 연산 투자에 총력을 다하고 있습니다[datacenterdynamics.com].

모델 학습에는 분산 학습 프레임워크를 통해 수천 개의 GPU/D1칩이 투입되고, 수 주간에 걸쳐 수조 회의 부동소수점 연산을 수행합니다. FSD의 경우 하나의 end-to-end 신경망이 아니라 수백개의 서브 네트워크로 구성된 모듈형 AI이므로, 각각의 모듈 (예: 차선인식, 객체예측, 경로계획 등)을 병렬로 혹은 순차적으로 훈련한 뒤 통합하는 형태를 취합니다[notateslaapp.com].
Optimus 로봇의 뇌 역시 이러한 FSD 비전모델을 공유하면서도, 추가적으로 강화학습이나 모션 제어를 위한 별도 네트워크 학습이 병행될 수 있습니다 (예: 로봇이 팔로 물체를 잡는 정책을 시뮬레이션에서 강화학습). 이처럼 다양한 학습 작업을 대규모 클라우드 리소스 위에서 수행하고 최적화하는 과정은 MLOps의 중추라 할 수 있습니다.
NVIDIA DGX Cloud를 활용하는 개발팀이라면 이 단계에서 클라우드 상의 수백~수천 GPU 노드를 할당받아 모델 학습을 돌립니다. 예를 들어, 수백만장의 합성 이미지로 물체인식 모델을 학습하거나, 수천개의 병렬 가상환경 에피소드를 통해 로봇의 강화학습을 진행하는 식입니다. Isaac Lab과 같은 툴킷은 이러한 학습을 돕는 프레임워크로, 시뮬레이터와 연동된 강화학습 등의 기법을 제공하여 시뮬레이션-학습 간 데이터 흐름을 최적화합니다[developer.nvidia.com].
클라우드의 탄력적 확장성 덕분에, 실험적으로 작은 모델로 시작해서 점차 큰 모델로 스케일업하거나 하이퍼파라미터 스윕(hyperparameter sweep)을 병렬 실행하여 최적 모델을 찾는 등 대규모 최적화 작업도 기민하게 수행할 수 있습니다. 학습이 진행되는 동안 MLOps 엔지니어들은 로그와 성능 지표를 모니터링하고, 목표한 정확도나 성능에 도달하면 다음 단계로 넘어갑니다.
4) 모델 평가 및 시뮬레이션 테스트(Validation & Simulation Testing)
학습이 완료된 모델은 곧바로 실세계에 배포되지 않고, 먼저 검증 단계를 거칩니다. 이 단계에서는 새로운 데이터로 모델을 시험하여 성능을 측정하고, 예상치 못한 오류 사례를 발견하는 데 주력합니다. 테슬라의 경우, 시뮬레이션과 현장 테스트를 모두 활용합니다.
한편으로는 자사가 구축한 시뮬레이터에 학습된 FSD/Optimus 모델을 넣어 다양한 가상 시나리오를 돌려보고, 다른 한편으로는 제한된 지역에서 실제 차량/로봇에 업그레이드된 모델을 투입해 모니터링합니다. 시뮬레이션은 특히 위험하거나 드문 상황을 반복적으로 재현하며 모델의 약점을 찾는 데 유용합니다.

예를 들어, 보행자가 갑자기 뛰어드는 상황을 수백 번 시뮬레이트하여 모델이 제대로 멈추는지 확인할 수 있습니다. 만약 특정 상황에서 오동작이 발견되면, 그 상황 데이터를 저장하여 다음 학습 사이클에 피드백 데이터로 추가합니다. 이를 데이터 엔진이라고도 부르는데, 테슬라가 자율주행 성능을 향상시키는 비결이 바로 이러한 실패 사례 수집 및 재훈련의 반복에 있습니다[notateslaapp.com].
NVIDIA의 Omniverse/Isaac 시뮬레이션 환경에서도 마찬가지로, 새로운 모델을 투입해 “무한 시나리오의 테스트”를 진행합니다[therobotreport.com]. 합성 데이터로 훈련한 모델은 현실에서 나타날 수 있는 분포 차이에 대해 시뮬레이션으로 한 번 더 단련될 필요가 있습니다.
예컨대, 조명이나 물체 배치가 학습때 본 것과 살짝 다르면 성능이 떨어질 수 있는데, 시뮬레이터에서 랜덤한 변화를 주어 모델이 보다 일반화된 성능을 갖추도록 합니다. 또한 개발자들은 시뮬레이션 테스트를 통해 모델의 정량적 지표(예: 인식 정확도, 경로 계획 성공률)를 측정하고, 이전 모델 대비 향상되었는지 분석합니다. 만약 목표에 못 미치면, 어느 단계에서 문제가 발생했는지 (데이터 편향? 모델 용량 부족? 등) 진단하고 파이프라인의 해당 부분을 개선한 뒤 다시 1단계부터 반복하게 됩니다. 이처럼 검증 및 테스트 단계는 최종 배포 이전의 품질 필터 역할을 하며, MLOps 파이프라인 상에서 자동 시뮬레이션 테스트 스크립트나 챔피언-척빈(Champion-Challenger) 평가 기법으로 구현됩니다.
5) 실시간 배포(Deployment) 및 모니터링

충분한 검증을 거친 모델은 이제 실제 로봇 시스템에 배포됩니다. 테슬라 Optimus의 예를 들면, 공장 내 작업중인 시제품 로봇에 새로운 인지/제어 모델이 OTA(Over-The-Air) 방식으로 업로드 되어 동작을 개시할 것입니다. FSD의 경우 테슬라는 무선 업데이트로 수십만 대 차량에 최신 베타 모델을 배포해왔는 데, 로봇도 이와 유사한 패턴으로 업데이트될 수 있습니다. 클라우드 MLOps 환경에서는 이러한 배포를 자동화하여, 특정 버전의 모델을 장비들에게 일괄 전송하고, 배포 성공 여부를 확인하며, 필요하면 이전 버전으로 롤백하는 기능까지 갖춥니다.
또한 실시간(inference) 최적화도 고려되어야 하는데, 테슬라가 발표한 바에 따르면 FSD/Optimus 모델은 차내 또는 로봇 내의 특수 AI칩 상에서 효율적으로 돌아가도록 컴파일됩니다[.braincreators.com]. 이는 곧 훈련된 가중치를 경량화하고, 여러 하위망(sub-network)을 각각 차량용 FSD 칩이나 로봇의 엣지 컴퓨팅 보드(Jetson 등)에서 병렬 실행하도록 배치하는 작업입니다. 이러한 최적 컴파일 및 할당을 거쳐야 비로소 모델이 실시간 시스템에서 제대로 동작합니다.
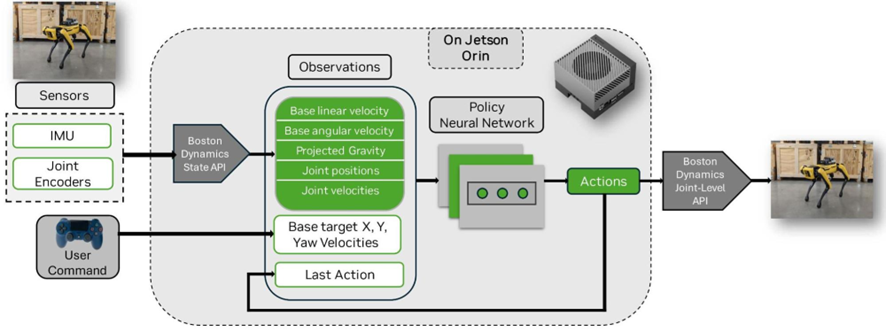
NVIDIA의 로봇 레퍼런스 플랫폼에서는 예컨대 “훈련된 정책을 Jetson AGX Orin 등에 배포하여 즉시 추론에 활용”할 수 있도록 end-to-end 스택을 제공하고 있습니다. 실제 Boston Dynamics의 사례처럼 시뮬레이션에서 강화학습으로 얻은 로봇 제어 정책을 손쉽게 로봇 하드웨어에 내려보 내 실행하는 것이 가능해진 것입니다[developer.nvidia.com].
배포 이후에는 모니터링과 지속적 개선(Continuous Monitoring & Improvement) 단계가 이어집니다. 실제 현장에 투입된 로봇/자율주행차는 여전히 예기치 못한 새로운 상황에 놓일 수 있으며, 이때 작동 로그와 센서 데이터가 다시 클라우드로 수집됩니다. 이는 다시 데이터 수집 단계로 들어가 파이프라인을 반복하게 합니다. 이렇게 폐쇄 루프를 이루는 MLOps 사이클 덕분에, 시스템은 시간이 지날수록 더 똑똑해지고 안정화됩니다.
테슬라의 경우 수십만 대 차량으로부터 매일 피드백 데이터를 모아 FSD를 개선해왔으며, Optimus도 공장에서 작업하며 쌓은 경험 데이터를 본사 클라우드로 전송해 학습에 반영할 전망입니다. 한편, NVIDIA의 Cosmos 사용자들도 초기에는 합성 데이터에 의존하더라도, 추후 실제 로봇을 배포한 현장에서 확보된 현실 데이터로 Cosmos의 세계 모델을 fine-tune하여 시뮬레이션의 현실감을 높이는 식으로 개선을 거듭할 수 있습니다. 결국 MLOps의 목표는 **“데이터와 모델의 지속적 동반 향상”**으로, Optimus와 Cosmos 모두 이 사이클을 효과적으로 구현함으로써 경쟁력을 키우고 있습니다.
종합적으로, 클라우드 기반의 데이터 학습 파이프라인은 AI 로봇 개발에서 혁신의 동력이 되고 있습니다. 테슬라 Optimus 사례에서는 방대한 실세계 데이터 + 자체 슈퍼컴퓨터 조합으로 데이터 중심 AI의 위력을 보여주고 있으며, NVIDIA Cosmos 사례에서는 시뮬레이션 생성 데이터 + 클라우드 GPU 인프라로 데이터 부족을 뛰어넘는 접근을 제시하고 있습니다. 두 길 모두 “실세계의 물리 문제를 AI로 풀기 위해서는 결국 데이터와 계산량에서 압도적 우위를 확보해야 한다”는 공통 원칙을 갖고 있습니다[datacenterdynamics.com].
테슬라는 자사가 선점한 실주행 데이터와 Dojo 컴퓨트로 그 우위를 유지하려 하고, NVIDIA는 자사의 하드웨어와 플랫폼을 클라우드로 개방하여 누구나 대규모 학습을 실현하도록 함으로써 업계 전반의 파이를 키우고 있습니다. 이렇게 발전하는 데이터 학습 파이프라인과 클라우드 인프라 덕분에, 자율주행차와 휴머노이드 로봇 같은 실세계 AI 시스템의 성능이 앞으로도 빠른 속도로 향상될 것으로 기대됩니다. 이는 제조, 물류, 모빌리티 등 다양한 산업에서 로봇 도입을 가속화하고, 인간의 개입을 최소화한 자율지능형 시스템을 실현하는 기반이 될 것입니다. 경쟁과 협력을 통해 성숙되어가는 Optimus와 Cosmos의 생태계가 과연 어떠한 AI 혁신을 이끌지 주목됩니다.
728x90'Humanoid' 카테고리의 다른 글
현대자동차그룹: 보스턴 다이내믹스를 통한 산업용 휴머노이드의 현실화 (1) 2025.06.03 25.6.3 대한민국 대기업의 휴머노이드 로봇 사업 현황 (0) 2025.06.03 NVIDIA DGX Cloud 및 Isaac Sim 기반 로봇 AI 학습 (0) 2025.05.28 테슬라 휴머노이드 로봇 Optimus 최근 6개월 종합 동향 (2023년 11월~2024년 5월) (1) 2025.05.24 Boston Dynamics Atlas vs Tesla Optimus 로봇 비교 분석 (2) 2025.05.22